


Machine learning (ML), Artificial Intelligence (AI), and Data Science have been the top trends for the last few years. However, what does it all mean?
In this article, we’ll focus on ML technology, its algorithms, how it can help various industries, and what are the successful business examples of machine learning implementation.
If you would like to read more about Pattern Recognition, which is a part of Machine Learning technology, we have a separate detailed article about it with graphs, schemes, and useful information in plain English (or, as plain English as possible.)
What Is Machine Learning Algorithms: Definition of Machine Learning
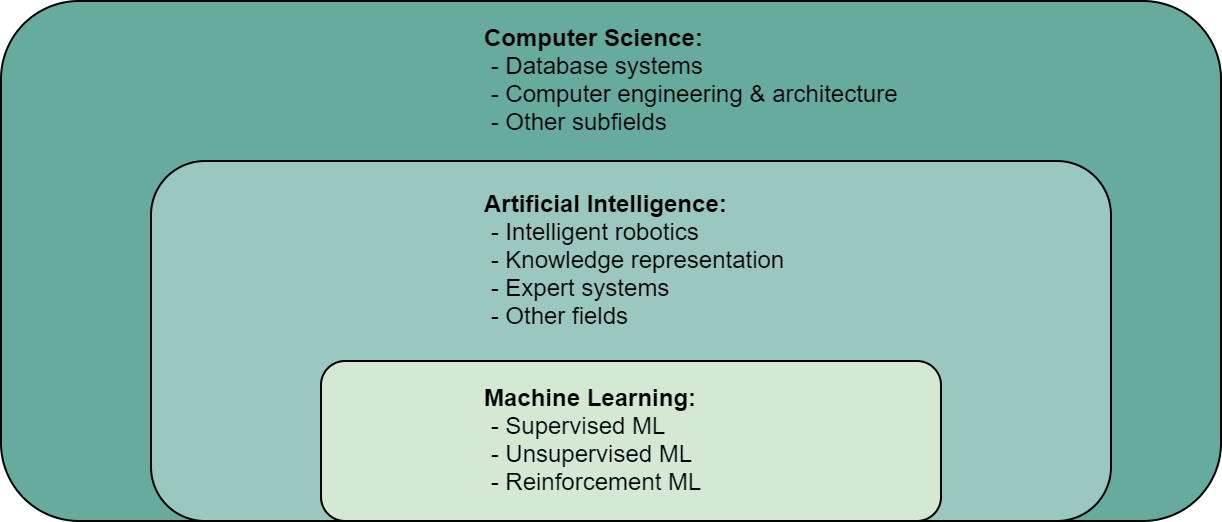
Before we define machine learning (ML) itself, let’s take a look at the general scheme of things. Machine Learning (ML) is a part of Artificial Intelligence (AI), which is a part of Computer and Data Science. Check out this helpful graph below:
What’s an algorithm? An algorithm is a sequence of instructions one must perform to solve a problem. For example, the flowchart below is a simple example of a straightforward algorithm.
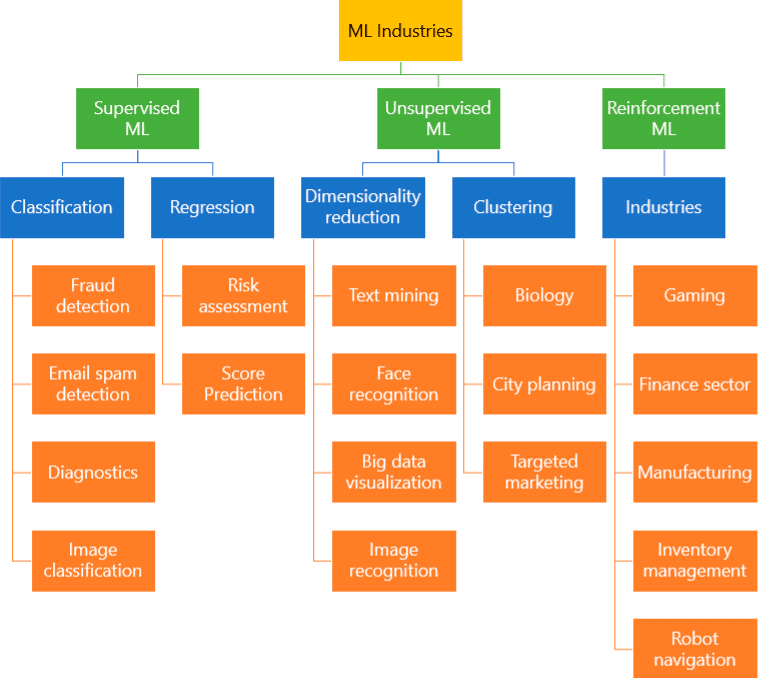
Machine Learning is a system of automated data processing algorithms that help to make decision-making more natural and enhance performance based on the results. The “learning” implies that the algorithm can glean new information and insights without being explicitly programmed. There are several models of machine learning:
- Supervised ML (the outputs are labeled, and the inputs are mapped to corresponding outputs)
- Unsupervised ML (the inputs are unlabeled, and the algorithms have to find patterns)
- Reinforcement ML (similar to supervised ML, but in this case, instead of a labeled output, there are rewards and the algorithm’s goal is to maximize rewards)
Artificial intelligence (AI) is a part of Computer Science that focuses on systems that can solve problems and perform tasks that require human (or human-like) intelligence. What does machine learning do in this process? It learns, just like a human(like) brain, acquiring new information.
Despite being a top trend in the last decade, machine learning as a term dates back to 1952, when an IBM expert, Arthur Samuel, wrote a program for playing checkers. For a long time, it was just a mathematical thing. However, when ML started to become more hands-on thanks to advances in computers, numerous industries started looking for ways to apply this empowering technology for their business purposes.
How Do Machine Learning Algorithms Work: Machine Learning Principles
Machine learning algorithms are like an infinite loop. The end goal depends on the type of ML algorithms, but technically, the data can be continuously improved by going through the cycles, such as these:
- Data (most of the time unlabeled) comes from various sources into one storage.
- The task of ML algorithms is to sort that data through
- Label it according to the settings
- Look for patterns in this data.
- Sorted data is translated into usable insights
- Insights are used to enhance and optimize business processes
- Business and learning processes are automated. Once you’ve got one batch of insights and adjusted your processes, you can’t simply stop. You need to continue working on making everything act like clockwork.
It all sounds quite straightforward (sometimes it even is straightforward, when you’re dealing with small amounts of incoming information). What is required for a good machine learning system?
- Capabilities for data preparation. You need to make sure you’ve got the hardware and software necessary to collect, process, analyze, integrate, and store this data.
- ML algorithms. There are numerous types and kinds of machine learning algorithms that we’ll take a look at a bit later in this article.
- Automation and iterative processes. So you don’t have to deal with the same thing over and over.
- Scalability. Even though right now, your data amount might be small, it’s better to prepare your system for future potential growth, because adjusting your project’s architecture once the product is alive is not an easy thing to do.
- Ensemble modeling. The idea here is that you use two or more algorithms at the same time to sync their results and get more precise results.
There are a lot of specific terms when it comes to machine learning. Let’s stop for a moment to take a look at the terms and understand what they mean.
- Epoch in machine learning. The epoch is complete when each sample in the dataset has had the chance to update the internal model parameters. Each epoch consists of one or more batches. The number of epochs is a parameter that states how many times the algorithm has to go through the entire training dataset.
- Learning rate in machine learning. The learning rate is a parameter that controls how the model is changed due to estimated errors each time the model weights are updated. Usually, the learning rate is a small positive value, somewhere between 1.0 and 0.0.
- Embedding in machine learning. Embeddings are the ways to transfer non-vector data into vector space, where ML algorithms can process various data pieces (for example, images, texts, graphs, etc.) TensorFlow’s Embedding Projector illustrates this idea well.
- Regression in machine learning. ML borrowed this term from statistics. Regression means the ability to predict the values of the desired quantity when the target quantity is continuous. For example, you’re trying to create a simple calculator for the price of a land piece based on its area. As you increase the area, the price increases as well, and the graph of the increase is called regression. There are different types of regression: Simple Linear Regression, Polynomial Regression, Support Vector Regression, Decision Tree Regression, and Random Forest Regression.
- Normalization in machine learning. The concept behind this technique is to change the values of numeric columns in the dataset to bring it to the common scale without changing the differences in the value ranges. Not every dataset has to go through normalization; it’s required when you have features with different ranges only.
- Online learning in machine learning. Online ML is a method in which data becomes available in sequential order, and the best predictor for future data is updated at each step, instead of learning on the entire training dataset at once to get the best predictor. This method is used, for example, in stock price predictions, when it’s not feasible to get an entire dataset for training at once.
Does every business need machine learning? As much as we’re tempted to say “YES!” because it would mean more work and clients for us, there are times when you don’t need ML to get insights. For example, if your business is small and incoming data can be easily analyzed and manipulated using simpler tools, like Google Spreadsheets.
However, ML is a lifesaver when it comes to businesses that deal with big data. Together with cloud computing power, machine learning algorithms enable fast and thorough processing and integration of data, whether it’s user behavior on your e-commerce website, DNA analysis for MedTech projects, or your ads’ effectiveness in an AdTech service.
What Algorithm Does Machine Learning Use
We’ve already mentioned how many machine learning algorithms are there, but let’s stop for a bit to talk about them in more detail.
There are four major ML models:
- Supervised Machine Learning Algorithms
- Linear Regression
- Logistic Regression
- Random Forest
- Gradient Boosted Trees
- Support Vector Machines (SVM)
- Neural Networks
- Decision Trees
- Naive Bayes
- Nearest Neighbor
- Semi-supervised Machine Learning Algorithms
- Unsupervised Machine Learning Algorithms
- k-means clustering
- t-SNE (t-Distributed Stochastic Neighbor Embedding)
- PCA (Principal Component Analysis)
- Association rule
- Reinforcement Machine Learning Algorithms
- Q-Learning
- Temporal Difference (TD)
- Monte-Carlo Tree Search (MCTS)
- Asynchronous Actor-Critic Agents (A3C)
When you are facing the choice of “which machine learning algorithm to use,” you need to consider several factors, including:
- What is the size, quality, and nature of your information?
- What’s your available computational time or, simply put, do you have a deadline?
- How urgent is the task?
- What do you want to do with the data itself and the results?
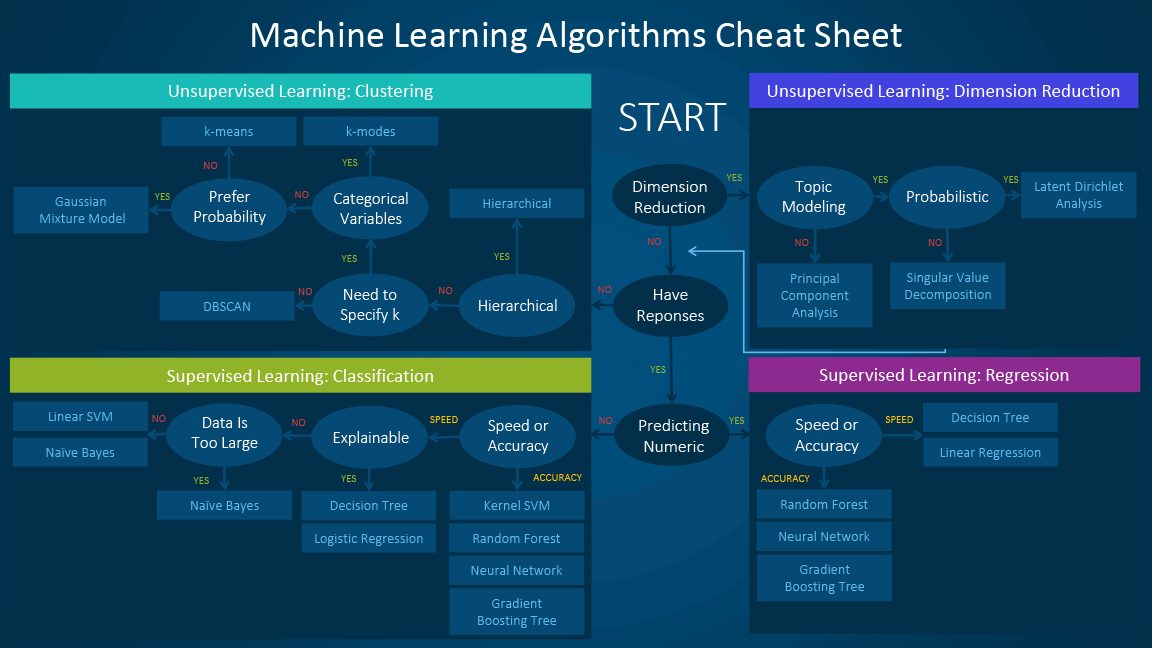
Check out this handy cheat sheet (by the way, this is also an example of an algorithm):
Machine Learning Algorithms Pros and Cons
The primary advantage of ML algorithms over traditional statistics is their ability to consume enormous numbers of records quickly and make predictions based on these incoming data that are more accurate. The result of these predictions is business intelligence insights that are valuable in the decision-making process.
Machine learning algorithms also can automate and improve numerous simple jobs, which helps to streamline business processes and optimize expenses (which is always a good thing in business.)
There are numerous business applications for ML technology, and we’ll talk about them later in the article. However, like any good thing, there are drawbacks and challenges to machine learning.
When anyone is making a decision, there is always some sort of bias involved. For example, if a person is trying to decide where to have dinner and with whom, numerous factors come into play: where did that person eat before, the time of the day, the mood, and the desire to talk (or not talk) during dinner. The answers most of the time will include a bit of bias based on previous experience.
With machine learning algorithms, bias can also cause a problem. On the one hand, large amounts of information get rid of some bias because it becomes negligible and gets lost in the other information (for example, one bad review of a restaurant gets lost in a thousand good ones.) On the other hand, if your incoming training dataset is biased, all your results will be biased as well, and this is when machine learning goes wrong (if, for example, your dataset contains mostly negative reviews.)
There are other challenges that you need to be aware of when dealing with data and training your ML algorithms. They aren’t a problem in themselves, but something you need to think about before you decide to implement machine learning algorithms into business processes.
Machine Learning and Big Data Challenges
Data Collection & Usage
If you simply collect information, nothing will happen (except for the fact that your storage will be full.) To transform incoming data into value-added business insights, you need to understand what kind of data you need and how you plan to use it.
Therefore, before you start to train your machine learning algorithm on a dataset, write down the goals for the algorithm and what kind of information can be helpful to reach that goal. For example, if you’re trying to decide which restaurant to pick, you don’t need a weather forecast for the day (unless you want to sit on the terrace) or the name of the sous chef (unless you’re tracking down a Michelin one).
If you end up getting that information as well, it won’t alter the results, but the process of wading through the numbers would take more effort and time. When we’re talking about big data projects, this issue becomes even more important.
Security
Cybersecurity is one of the hottest topics these days. With so many people sharing their personal information and millions of bots generating even more online data, it’s relatively easy to sway public opinion toward one or another decision. Think of Brexit and the Cambridge Analytica scandal (the Brexit movie shows it quite well). Or Equifax leaks – it’s all about the illicit use of collected data.
Therefore, when you are collecting information, you need to make sure you’re not violating the law. This is especially sensitive due to the General Data Protection Regulation law that came out in May of 2018. So far, GDPR works only within the bounds of the European Union. Nevertheless, you need to remember that if, for example, you’re located in the United States yet you have people from the EU come to your website or use your application, you need to make sure you get consent from them for data collection.
When cybersecurity meets machine learning, you need to make sure the data you collect is regulated (clear permissions for different levels of users), informed (official consent agreement), monitored, and transparent. The data collected in this way can be used safely for training your ML algorithms.
Data Validation
When you have incoming data from several sources, you need to pay attention to the credibility of your data. Is there any information that can cause harm? Semi-supervised machine learning algorithms help with automating the labeling process. They can go through unlabeled data and compare it to the available examples of already-labeled information.
Right Algorithms
Every machine learning model has a purpose and is designed to perform specific tasks. Therefore, one of the challenges in ML is choosing the right algorithm that would bring you the insights you are looking for. For example, an unsupervised algorithm won’t be able to label your data correctly because its primary purpose is to look for patterns, and vice versa. Before you implement ML, once again, you need to write down your expectations from this technology and what is the end goal.
Training Dataset
When you’re training your machine learning algorithm, you need a good and large training dataset, so that the algorithm can identify the major patterns, information, and insights. If your dataset is small, the results might be very biased. The sources for data can come from data gathering services (for example, your business’s Google Analytics account), sample datasets (faux data), or they can be purchased from a third party. Whatever you do, remember that your data needs to be credible and validated, it should be relevant for the algorithm’s purpose, and it should be cleaned. It also should be legally obtained data (for obvious reasons.)
In some cases, you might use machine learning algorithms for small data sets, but most of the time, it’s not cost-effective. Therefore, either make sure you’ve got enough data or don’t invest in ML algorithms at this point.
Data Noise
According to IBM researchers, “Pareto’s Principle applies: 80% of a data scientist’s valuable time is spent simply finding, cleansing, and organizing data, leaving only 20% to perform analysis.”
Data noise is any data that isn’t relevant to the ML algorithm’s purpose. As we’ve mentioned above, in our example with the restaurant. If you are looking for a restaurant with a specific sous-chef or a dish, getting information about sous-chefs at restaurants or their menus would be necessary for your purpose. If, however, you’re looking for a good place to eat in the vicinity, the name of the sous-chef would be data noise, because it would mean absolutely nothing to you. Data noise can be incomplete information, inconsequential data, anomalous bits, and information that can’t be identified.
Why is this important? Because data noise can dilute your machine learning algorithm’s efficiency, the results you’ll get will not be as precise as they can be. For example, let’s consider the table below with the average imaginary salary calculation:
| SALARY SOURCE #1 | SALARY SOURCE #2 | |
|---|---|---|
| Salary 1 | 10 | 10 |
| Salary 2 | 15 | 15 |
| Salary 3 | 43 | 43 (Anomaly) |
| Salary 4 | 12 | 12 |
| AVERAGE: | 20 | 12.3 |
As you can see, 43, in this case, was an anomaly, but if this data noise isn’t taken out of consideration, the results are not correct. As you can see, if one person is getting more money than the three others combined, then the average would be considerably skewed. If that anomalous salary is taken out of the calculations, then the average becomes much more realistic.
Training ML Model
Once you’ve sorted out the purpose of the machine learning technology for your particular business and understood what kind of information you’d like to collect, it’s time actually to train your machine learning model. There is no need to reinvent the wheel these days because there are numerous tools available for it, including TensorFlow, Valohai, PyTorch, Apache Spark, and many others.
When To Use Machine Learning: Machine Learning Algorithms and Their Use Cases
- Self-driving cars from Google – that’s machine learning.
- Online recommendations from Netflix – machine learning.
- Knowing what people say about you online – natural language processing and deep learning ML algorithms for sentiment analysis
As we mentioned above, numerous businesses already reap the benefits of machine learning algorithms.
Machine Learning in Banking and Financial Services: A Case Study
Various financial services and banks deal with a lot of numerical data, and this is one of the best uses of machine learning algorithms for anomaly detection and fraud prevention. The insights, besides protecting from high-risk clients and signs of manipulations, also help to identify investment opportunities or use machine learning algorithms for trading.
Fraud Detection
One of the most prominent applications of machine learning in the banking sector is fraud detection. Banks deal with a vast amount of transaction data daily, making it challenging to manually identify fraudulent activities. Machine learning algorithms can help automate this process and improve accuracy:
How it works:
- Data Collection: Banks collect transaction data, including customer information, transaction history, and location data.
- Feature Engineering: Relevant features are extracted from the data, such as transaction amount, time, and location.
- Model Training: A machine learning algorithm (e.g., Random Forest, Support Vector Machine) is trained on a labeled dataset of fraudulent and legitimate transactions.
- Model Deployment: The trained model is deployed in real time to analyze new transactions.
- Fraud Detection: The model flags suspicious transactions based on learned patterns and anomalies.
Benefits:
- Reduced financial losses: Early detection of fraudulent transactions helps banks minimize financial losses.
- Improved customer experience: By preventing fraudulent activities, banks can enhance customer trust and satisfaction.
- Regulatory compliance: Machine learning can help banks comply with anti-money laundering regulations.
Government: A Case Study
Public Safety and utility agencies also can benefit from the insights provided by data mining and machine learning. One of the implementation areas is energy efficiency, which helps to minimize the expenses and the payload. Machine learning algorithms for face recognition also help with surveillance and protection from identity theft.
Predicting Social Unrest
Governments can leverage machine learning to analyze vast amounts of data and predict potential social unrest. This can help them proactively address issues and maintain stability.
How it works:
- Data Collection: Governments collect data from various sources, including social media, news articles, and economic indicators.
- Natural Language Processing (NLP): Text analysis techniques are used to extract sentiment and identify potential indicators of unrest, such as protests, riots, or civil disobedience.
- Predictive Modeling: Machine learning algorithms are trained on historical data to predict the likelihood of social unrest based on identified indicators.
Benefits:
- Early Warning Systems: Governments can establish early warning systems to detect potential unrest and take preventive measures.
- Resource Allocation: Predictive analytics can help governments allocate resources effectively to address areas at risk of social unrest.
- Improved Governance: By understanding public sentiment and identifying potential flashpoints, governments can improve their governance and responsiveness to citizen concerns.
Healthcare & Medical Industry: A Cast Study
Machine learning for healthcare predictions is a very fast-growing trend due to wearable devices and sensors. Thanks to them, the patient’s data can be provided for the machine learning algorithms in real-time, helping to save lives.
Big data analytics, in combination with machine learning algorithms, can also help in analyzing trends or identifying red flags in terms of diagnosis and treatment.
Machine learning algorithms for image processing and machine learning algorithms for image classification are the technologies behind the ability to identify abnormal formations in various human organs and help early cancer detection, among other causes.
HUSPI had a chance to provide IT consulting services to one such project called Homeopath. Using machine learning algorithms for pattern recognition, machine learning algorithms for prediction, and machine learning algorithms for regression, the system, once launched, would continuously update its records with newer findings, making the future patients’ treatments more precise.
Personalized Treatment Plans: Case Study
Precision medicine is a growing trend in healthcare, and machine learning plays a crucial role in enabling it. By analyzing vast amounts of patient data, machine learning algorithms can help healthcare providers develop personalized treatment plans tailored to individual patients’ needs.
How it works:
- Data Collection: Healthcare organizations collect electronic health records (EHRs), genomic data, clinical trial results, and other relevant patient information.
- Feature Engineering: Relevant features are extracted from the data, such as patient demographics, medical history, genetic markers, and medication responses.
- Model Training: Machine learning algorithms (e.g., decision trees, random forests, neural networks) are trained on large datasets to identify patterns and correlations.
- Personalized Recommendations: The trained models can provide recommendations for the most effective treatments, medications, or clinical trials based on a patient’s specific characteristics.
Benefits:
- Improved Patient Outcomes: Personalized treatment plans can lead to better treatment outcomes and reduced side effects.
- Reduced Healthcare Costs: By optimizing treatment decisions, healthcare organizations can reduce costs associated with ineffective or unnecessary treatments.
- Drug Discovery: Machine learning can accelerate drug discovery by identifying new drug targets and optimizing clinical trials.
Machine Learning in Retail and E-commerce: A Case Study
With the help of machine learning algorithms for recommendation systems, retail, and e-commerce businesses can enjoy higher customer acquisition. Retailers can also capture data, analyze it, and use it to provide a personalized shopping experience, implement marketing campaigns, optimize prices, manage supply planning, and get customer insights.
Customer Segmentation Case
Retailers and e-commerce businesses can leverage machine learning to segment customers into distinct groups based on their demographics, behaviors, and preferences. This enables targeted marketing campaigns and personalized recommendations.
How it works:
- Data Collection: Retailers collect customer data, including purchase history, demographics, browsing behavior, and interactions with marketing campaigns.
- Customer Segmentation: Machine learning algorithms (e.g., clustering algorithms, decision trees) are used to identify distinct customer segments based on shared characteristics.
- Personalized Recommendations: Retailers can use these segments to deliver personalized product recommendations, targeted promotions, and relevant content.
Benefits:
- Increased Customer Engagement: Personalized recommendations can enhance customer engagement and loyalty.
- Improved Sales: Targeted marketing campaigns can lead to higher conversion rates and increased sales.
- Enhanced Customer Experience: By understanding customer preferences, retailers can provide a more tailored and satisfying shopping experience.
Machine Learning in Oil, Gas, and Energy: A Case Study
Machine learning algorithms for classification help to analyze the minerals in the ground, find new energy sources, and streamline oil and gas distribution to make it cost-effective. Unsupervised machine learning algorithms for pattern detection are also used to diagnose sensor failures or manufacturing defects that would otherwise go undetected.
Predictive Maintenance
Oil and gas companies can use machine learning to predict equipment failures and optimize maintenance schedules, reducing downtime and improving operational efficiency.
How it works:
- Data Collection: Sensors collect data from various equipment components, such as temperature, vibration, and pressure.
- Feature Engineering: Relevant features are extracted from the data, such as sensor readings, equipment age, and maintenance history.
- Predictive Modeling: Machine learning algorithms (e.g., time series analysis, and regression models) are trained to predict equipment failures based on historical data and patterns.
Benefits:
- Reduced Downtime: Predictive maintenance can help identify potential equipment failures before they occur, minimizing downtime and production losses.
- Optimized Maintenance Schedules: By predicting equipment lifespans, companies can optimize maintenance schedules, reducing costs and improving efficiency.
- Improved Safety: Predictive maintenance can help identify potential safety hazards, preventing accidents and injuries.
ML in Transportation, Logistics, and Automotive: A Case Study
What is the most efficient route? How to increase traffic capacity? How do they optimize the traffic lights system in the city? All of these questions can be answered with the help of insights from machine learning algorithms. Have you ever used Waze and enjoyed its ability to adapt the route on the fly to the best possible one given the set of filters? Yep, this is machine learning at work.
Data analysis and modeling are also helpful tools for companies such as delivery providers, public transportation, and other organizations that deal with transport.
Driverless cars are also powered by machine learning algorithms, especially their automatic energy response systems. Besides real-life examples, it is also used in the Gaming industry. For example, Grand Theft Auto uses a collision detection machine learning algorithm for moving people and cars.
Route Optimization Case
Transportation and logistics companies can use machine learning to optimize routes, reduce fuel consumption, and improve delivery efficiency.
How it works:
- Data Collection: Companies collect data on road conditions, traffic patterns, delivery locations, and vehicle performance.
- Route Optimization Algorithms: Machine learning algorithms (e.g., genetic algorithms, simulated annealing) are used to find the most efficient routes based on various factors such as distance, time, and fuel consumption.
- Dynamic Routing: Machine learning models can adapt routes in real time based on changing conditions such as traffic congestion or unexpected events.
Benefits:
- Reduced Fuel Consumption: Optimized routes can lead to significant fuel savings.
- Improved Delivery Efficiency: Efficient routes can reduce delivery times and improve customer satisfaction.
- Reduced Environmental Impact: Optimized routes can help reduce carbon emissions and improve sustainability.
Advertising Technology (AdTech)
AdTech businesses heavily lean on machine learning algorithms. One of the reasons for this is the fact that AdTech is one of the true Big Data industries. The incoming ads, the outgoing ads, the prices per ad, all payments to third parties and fees, etc. – all of this has to be accounted for.
Similar to ML in e-commerce, machine learning algorithms for advertising help to make sure
- there is no ad fraud involved
- customers are targeted with ads they would like (based on recommendation engines and user preferences)
- publishers got their money
- and everyone is happy.
AdTech companies also leverage machine learning to deliver highly personalized ads to users, improving ad targeting and increasing click-through rates.
How it works:
- Data Collection: AdTech platforms collect data on user behavior, demographics, interests, and browsing history.
- User Profiling: Machine learning algorithms are used to create detailed user profiles based on this data.
- Real-time Bidding: In real-time auctions, machine learning models predict the likelihood of a user clicking on an ad and determine the optimal bid price.
Benefits:
- Improved Ad Relevance: Personalized ads are more likely to resonate with users, increasing click-through rates and conversion rates.
- Higher ROI: Effective ad targeting can lead to a higher return on investment for advertisers.
- Enhanced User Experience: Relevant ads can improve the overall user experience by reducing ad fatigue.
Should You Use Machine Learning for Business?
Machine learning algorithms for data science and analysis are here to stay. Does every single business need it? Probably not, since numerous businesses are small and don’t generate a lot of data.
At the same time, it is important to understand that with the technological progress that we are witnessing today, the amount of information will continue to increase at an exponential level, and it might be wise to prepare your product’s architecture for the possibility of ML.
Need IT consultation in terms of machine learning algorithms or how to prepare your infrastructure for the incoming data? Contact us – we can help.
Wondering about time-to-value?
Request a no-obligation discovery call and receive a preliminary estimate tailored to your KPIs.
P.S. HUSPI has been named #1 among the TOP Artificial Intelligence companies in Poland.