


In our previous article, we explored the critical role of standardized hospital records data in achieving seamless interoperability across healthcare systems. This interoperability unlocks a range of benefits, from smoother care coordination for patients to improved efficiency for healthcare providers. It paints a picture of a future where a patient’s medical history seamlessly travels with them, eliminating the need for repetitive tests and ensuring a more holistic approach to treatment.
However, the path to this interconnected healthcare utopia can be challenging. As we delve into the practicalities of implementation, we encounter a familiar foe: the HL7 standards. While widely adopted, these standards, particularly HL7 v2, present a unique challenge.
The very flexibility designed to accommodate diverse healthcare systems can lead to inconsistencies in implementation across hospitals.
This creates a situation where, instead of a smooth information highway, we encounter a network of winding backroads, each with its own interpretations and customizations.
In this article, we’ll draw on our own experiences integrating HL7 v2 with various hospitals. We’ll delve into the specific challenges encountered, and the roadblocks they create, as well as explore potential solutions to navigate this complex landscape. By understanding these challenges, we can work towards a future where the promise of interoperability becomes a reality.
(And yes, we won't wait until the very end of the article to say that we've got experience in dealing with all the challenges that we present below, therefore, feel free to contact us in case you need EMR integration - on any side of this equation.)
The Complications of HL7 v2
The HL7 standard has been a healthcare IT workhorse since the 1980s. It’s like that reliable old toolbox – sure, there’s a newer, flashier model with all the bells and whistles (think FHIR with its JSON format), but HL7 v2 still gets the job done.
Here’s where things get interesting, though.
One challenge is that different hospitals use different versions of HL7 v2 – some use v2.3, some v2.6, and some use v2.9. (And there are more options in between these.) The differences are slight, but they are present.
The other challenge is that while HL7 provides a framework, hospitals have a knack for customizing their medical systems to fit their specific workflows. It’s not like they’re throwing the rulebook out the window – they’re technically following the standard. But, just like that trusty toolbox, everyone seems to have their own way of arranging the wrenches. This flexibility, while well-intentioned, can make it a real head-scratcher when you’re trying to create a one-size-fits-all integration solution.
Now, let’s take a real-world example. We have a client who developed a fantastic utilization review product that seamlessly integrates with EMR systems. Sounds perfect, right? Here’s the catch: when they approach hospitals to showcase their product, they need to have a clear conversation about data requirements. We, on the back end, meticulously create a list of specific HL7 segments our system needs to function – things like ADT (Admission-Discharge-Transfer) and PID (Patient Identification Data). These segments are like the building blocks we need to analyze utilization patterns.
The hospital’s IT team then sets up a secure connection (think TCP/IP port) for data transfer. We developed a data parser that received these files, processed them, and provided analysis of the data in it.
Data Mapping: What segments do you need?
Here’s where the plot thickens – data mapping becomes a bit of a maze. Imagine this: you’ve identified the initial set of data segments you need. You head to the hospital, present your list, and their EMR administrators get to work, crafting the data file you require. Now, this service isn’t exactly complimentary.
The kicker? If you later realize you need an additional data segment, well, that’s another round of billable fees. The issue is that we don’t have complete transparency into their cost structure. It’s a bit of a black box – we know they create the file, but the specifics remain a mystery.
This lack of clarity, coupled with the upfront nature of specifying data needs, creates a rigid environment at the project’s outset. You practically have to predict the future and anticipate every single data point you might need from the get-go (or be prepared for additional costs.)
| Segment | Description |
|---|---|
| MSH | Message Header |
| EVN | Event Type |
| PID | Patient Identification |
| NK1 | Next of Kin |
| PV1 | Patient Visit |
| OBR | Observation Request |
| OBX | Observation Result |
| ORC | Common Order |
| NTE | Notes |
| IN1 | Insurance |
| GT1 | Guarantor |
Data Mapping: How standard is the data?
This reliance on HL7 v2 throws a curveball at our development process. Each hospital, despite adhering to the core standard, implements it with its unique spin. It’s like everyone having the same recipe book but making substitutions based on personal preference.
For instance, we’ve encountered situations where a field documented as having three subfields (Patient’s ID, Account number, and Code) is condensed into a single primary field at a specific hospital because it was just easier for the IT personnel to do it that way (they didn’t use the other two fields).
This might seem like a minor detail, but for our system, it’s a data-parsing nightmare. Our code expects to find specific information within those subfields, and when it’s all lumped together, the mapping goes haywire.
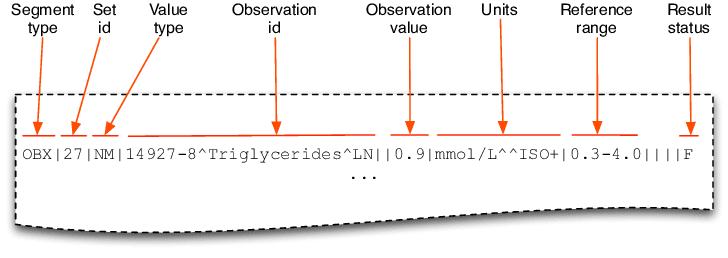
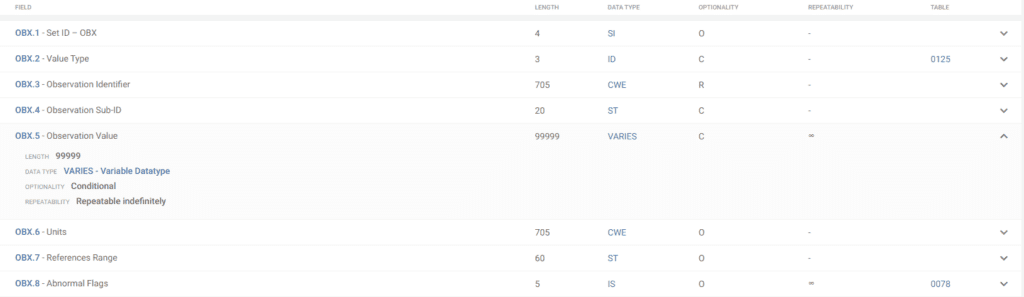
Another example of the flexibility, and potential challenges, within HL7 v2 implementations lies within the OBX segment (see below). Specifically, the OBX-5 field, which houses the observation value, utilizes a “VARIES” data type and is specifically designed to carry the actual content of a laboratory or clinical observation report.
Because the OBX segment uses VARIES, this essentially means the format and structure of the data within this field can vary significantly. While this flexibility allows for the inclusion of diverse data types, it can also complicate integration efforts. The data in OBX-5 could be a simple text string, or it might require further parsing into subfields using a structured format like CWE (Coded With Explanations). This variability necessitates careful analysis of the specific data format used by each hospital to ensure accurate data mapping during integration projects.
- Content Types: OBX.5 can handle various report formats, including:
- Plain Text: This is the simplest format, consisting of regular text.
- Rich Text: This format allows for some basic formatting like bolding or italics within the text.
- PDF: OBX.5 can even handle sending a complete PDF document containing the report.
- Line Breaks: If you need to include line breaks within the report content (like creating new paragraphs), you can use the tilde character (~) to indicate them.
- Long Reports: HL7 messages have a limit on the amount of data they can carry in a single field. If your report content in OBX.5 exceeds this limit, the message will be split across multiple OBX segments.
Format (received by downstream systems):
Plain Text Example:
OBX|6|TX|1009^ADDITIONAL PROGRESS NOTES 2|6|Link on 12/22/99 by: JENSEN, JAMES [319] of: Example of a binary scan||||||F|Rich Text Example:
OBX|1|TX|85502^ODI Visit Rich Report|1|{\E\rtf1\E\sste1...||||||F|^<Format>^^base64^<encapsulated data> Example:
OBX|1|ED|51000^VISIT SUMMARY: W/O HISTORY (HTML)|1|^PDF^^base64^JVBERi0xLjQl77+977+977+977+9MSAwIG9iaiAgPDwgICAgL0F1...||||||F| Data Mapping: Custom HL7 v2 segments
Another hurdle we encounter is the use of custom HL7 v2 segments. While these segments adhere to the core HL7 v2 standards (or not), they’re tailored by specific hospitals to meet their unique needs – think of them as specialized tools within the HL7 v2 toolbox. The challenge lies in their unpredictability. Since these segments are created in-house, we have no way of anticipating them until the hospital IT team flags their existence. This lack of foresight can introduce delays and require additional mapping efforts during integration projects.
Why are custom segments used? Perhaps it was historically useful; perhaps there was no other way around it; or perhaps it was just simpler that way for the given hospital.
While our current product works well for a limited number of clients, scalability becomes a major hurdle. The need for deep dives into individual hospital data files to ensure proper mapping makes it incredibly difficult to seamlessly integrate our service with a large number of hospitals or insurance companies simultaneously. It forces us to create essentially bespoke instances for each client, rather than having a single, universally compatible solution. This not only hinders scalability but also increases development and maintenance costs.
Example of custom segments in HL7
The presence of Z segments (Zxx) in HL7 implementations introduces another layer of complexity. These segments offer healthcare institutions the flexibility to include non-standardized data elements, essentially creating custom fields within the message structure.
While this approach caters to specific hospital requirements, it presents a challenge for integration. The format and content of these Z segments can vary significantly, often requiring the development of custom parsers to interpret the data accurately. This additional development effort can impact project timelines and resource allocation.
Strategies for Smoother HL7 v2 Integration:
Standardization Efforts Within Hospitals: While hospitals have flexibility with HL7 v2, encouraging internal standardization around data formats and interpretations can significantly reduce mapping headaches. Consistency is key to true interoperability.
Interface Engines and Mapping Tools: These handy tools can act as data translators, mediating between your system and the hospital’s specific HL7 v2 implementation. Think of them as bridge builders, easing communication across the data divide.
Clear Communication and Collaboration: Open and frequent communication between your team and the hospital’s IT department is crucial. Discussing data needs upfront, sharing mapping specifications, and troubleshooting together can go a long way in ensuring a smooth integration process.
Potential Solutions and the Future
The data mapping challenges presented by HL7 v2 implementations highlight the need for innovative solutions. Here at [your company name], we’re actively exploring the implementation of FHIR (Fast Healthcare Interoperability Resources) standards. FHIR offers a breath of fresh air – it leverages JSON, a widely used and human-readable format, eliminating the customization headaches of HL7 v2.
With FHIR, the data structure is not only standardized, but it’s also remarkably flexible. You can seamlessly add or remove fields without disrupting the entire system. This not only simplifies data parsing but also streamlines integration with other systems, potentially even allowing for smoother integration with tools like Epic Sharable Apps.
However, we recognize that HL7 v2 remains a workhorse in the healthcare IT landscape. Many institutions rely on it, and a complete transition won’t happen overnight. The key lies in a multi-pronged approach. We’ll continue to support HL7 v2 integrations while actively advocating for and implementing FHIR where possible. As the industry embraces FHIR’s inherent interoperability advantages, the data exchange landscape will undoubtedly become more streamlined.
This future holds immense promise – a future where healthcare data flows freely, enabling seamless collaboration between providers, improved patient care, and a more efficient healthcare ecosystem overall. By embracing innovative solutions like FHIR, we can navigate the current hurdles and unlock the true potential of interoperable healthcare data exchange. While exact statistics might be difficult to find, the trend is clear: HL7 v2 remains dominant but FHIR adoption is on the rise, driven by its potential to improve healthcare data exchange.
Wondering about time-to-value?
Request a no-obligation discovery call and receive a preliminary estimate tailored to your KPIs.